DEUG MIAS 2iŤme annťe
MIO2-2
Option Informatique Approfondie
Projet Rťťcriture
1998-99
Pascal Manoury
ß I -- Rappels : pointeurs, liste, arbres
1. Les listes
(1.a) Considťrations abstraites
Les listes sont des structures de donnťes permettant un
stockage et un traitement sťquentiel des donnťes. Abstraitement,
on peut dťfinir les listes de faÁon rťcursives selon deux
clauses :
- soit la liste ne contient aucun ťlťment, on dit alors
qu'elle est vide, on notera Nil;
- soit la liste commence par un ťlťment x et se poursuit par
la liste xs, on notera Cons(x,xs).
Les symboles Nil et Cons sont appelťs constructeurs des
listes. Toute liste est construites en utilisant ces
constructeurs. Par exemple, la liste contenant les entiers 1, 2 et 3
est obtenue en ťcrivant Cons(1,Cons(2,Cons(3,Nil))).
On n'accťde ``directement'' qu'au premier ťlťment d'une liste et
quŗu reste de la liste, lorsque celle-ci n'est pas vide. Pour
effectuer ces opťrations, on se donne les opťrateurs hd et tl
que l'on dťfinit par les ťquations :
| hd(Cons(x,xs)) |
= |
x |
| tl(Cons(x,xs)) |
= |
xs
|
Le comportement de hd et tl n'est pas spťcifiťpour la liste
vide Nil : ces opťrateurs sont partiels. Ces opťrateurs sont
appelťs accesseurs ou destructeurs des listes.
Remarque : on a, pour toute liste xs non vide
xs = Cons(hd(xs), tl(xs))
A partir de ces seules primitives, on peut dťfinir TOUTES les
fonctions (calculables) sur les listes.
Exemple (1) : Calcul de la taille d'une liste : fonction size dťfinie par
rťcurence sur son argument
| size(Nil) |
= |
0 |
| size(Cons(x,xs) |
= |
1+size(xs)
|
Supposons que nous disposions en PASCAL d'un type D donnťet
d'un type DList pour les listes d'ťlťments de type D ; des
constructeurs Nil et Cons ; des destructeurs hd et
tl. On peut dťfinir la fonction size, en PASCAL
Function size(xs:DList) : Integer;
Begin
If xs = Nil then size := 0
Else size := 1 + size(tl(xs));
End;
(1.b) Considťration plus concrŤtes
On veut pouvoir, ŗloisir, ajouter, retrancher des ťlťments
d'une liste, voire mettre deux listes bout ŗbout. Le nombre
d'ťlťments contenus dans une liste (que l'on appelle sa taille) peut donc varier de faÁon arbitraire et l'on ne veut pas
a priori fixer de limite maximum (la limite minimum est toujours
0) Pour rťaliser cela, on a recours au mťcanisme d'allocation
dynamique de mťmoire mettant en oeuvre, en PASCAL, le
mťcanisme des pointeurs.
Les pointeurs (rappels)
Un pointeur n'est rien d'autre qu'une rťťrence ŗun endroit de
la mťmoire de la machine appelťe adresse mťmoire. En
PASCAL, toutes les donnťes manipulťes ont un type. En PASCAL donc,
tout pointeur est toujours un pointeur vers un objet d'un certain type.
On n'apas de pointeur en gťnťral, mais toujours un pointeur vers
donnťe d'un type donnť. Soit D un type de donnťes, pour
dťclarer le type DPtr des pointeurs vers une donnťe de
type D, on utilise la syntaxe
Type
DPtr = ^D;
Le type D peut Ítre aussi complexe que l'on veut : un entier,
un tableau, un enregistrement, un autre pointeur, etc ...
On dťclare les variables de type pointeur selon la syntaxe usuelle
Var
p : DPtr;
On accŤde ŗla valeur pointťe par p par la syntaxe
p^ L'expression p^ est de type D, lorsque DPtr
est dťfinie comme D^. On a alors droit sur p^ ŗpresque1
toutes les opťrations autorisťes sur les variables de type D
- si D est le type Integer, on peut ťcrire
p^+0 ou p^:=0
- si D est un type tableau, on peut ťcrire
p^[2]
- si D est un type enregistrement dont l'un des champs est
c, on peut ťcrire
p^.c
Exemple (2) : Petit exemple de pointeur(s) sur un entier
Program exm1;
Type
intPtr = ^Integer;
Var
i : Integer;
p : intPtr;
q : intPtr;
Begin
i := 5;
writeln("i = ", i);
new(p);
p^ := i;
writeln("p^ = ", p^);
p^ := i+1;
writeln("i = ", i, " p^ = ", p^);
q := p;
writeln("q^ = ", q^, " p^ = ", p^);
p^ := p^+1;
writeln("q^ = ", q^, " p^ = ", p^);
End.
Listes chaÓnťes (rappels)
Pour reprťsenter les listes, nous utiliserons des enregistrements
comprenant deux champs : un champs contenant un pointeur sur un
ťlťment de liste, un champs reliant cet ťlťment au reste de la
liste. Une liste est un pointeur sur un tel enregistrement. Nous
supposons que les ťlťment de la liste sont d'un certain type D.
Type
DPtr = ^D;
DList = ^DItem;
DItem =
Record
head : DPtr;
tail : DList;
End;
Dťfinit alors les constructeurs et destructeurs des listes. Les cas
de la liste vide est simple : les listes ťtant des pointeurs, on
utilise le pointeur nul Nil. Les autres opťrateurs sont
dťfinis par :
Function Cons(x:D, xs:DList) : DList;
Var aux : DList;
Begin
new(aux);
new(aux^.head);
aux^.head^ := x;
aux^.tail := xs;
Cons := aux;
End;
Function hd(xs:DList) : D;
Begin
hd := xs^.head^;
End;
Function tl(xs:DList) : DList;
Begin
tl := xs^.tail;
End;
Exercice (1) : Ecrire une fonction last qui retourne la valeur (de type
D) du dernier ťlťment d'une liste non vide.
Remarque (1) : Il n'est pas toujours possible d'obtenir une
fonction hd retournant un objet de type D En effet, en
PASCAL, le type de retour d'une fonction doit Ítre simple : un
entier, un rťel, un pointeur, etc... Si l'on veut donc constituer
des listes d'objets plus complexes, la fonction hd ne pourra
retourner qu'un pointeur sur une structure reprťsentant l'objet.
Exercice (2) : Listes d'association avec ses primitives assoc, memassoc, addassoc (sans duplication de clť)
(1.c) Listes chaÓnťes (discussion)
Une opťration courante sur les liste est l'opťration de concatťnations que nous noterons append. Selon notre habitude,
nous la dťfinissons par le systŤme d'ťquations rťcursives :
| append(nil, ys) |
= |
ys |
| append(Cons(x,xs), ys) |
= |
Cons(x, append(xs,ys))
|
En utilisant les primitives dťfinies en [X], nous
dťfinissons la fonction append comme
Function append(xs:DList, ys:DList) : DList;
Begin
If xs = Nil then append := ys
Else append := Cons(hd(xs), append(tl(xs), ys))
End;
Soient l, l1 et l2 trois listes. Aprťs exťcution
de l'instruction
l := append(l1, l2);
on obtient un rťsultat illustrťpar la figure suivante :
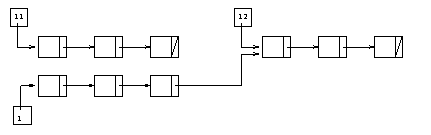
oý la liste l1 a ťtťdupliquťe.
Ce rťsultat n'est pas toujours souhaitable : il consomme inutilement
de la mťmoire si l'on ne veut plus se servir de la liste originelle
l1. Dans ce cas, on aimerait plutŰt obtenir :
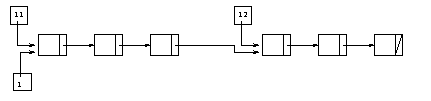
Pour obtenir ce second rťsultat, il faut pouvoir modifier la
valeur du champs tail de la derniŤre cellule de l1 en
lui donnant la valeur l2 et l peut alors recevoir la
valeur l1.
Considťrons maintenant le problŤme suivant : obtenir une liste
xs' ŗpartir d'une liste xs dont on modifie la valeur du premier
ťlťment. En n'utilisant que nos primitives actuelles, nous
ťcrivons une fonction modifHead :
Function modifHead(xs:DList, x:D) : DList;
Begin
modifHead := Cons(x, tl(xs));
End;
Ici encore, nous avons crťť(par l'appel ŗCons)
une2
nouvelle cellule contenant x alors que l'on aurait peut Ítre
simplement voulu modifier en place la valeur du premier
ťlťment.
Pour tenir compte de ces remarques, il nous faut sortir du cadre
purement fonctionnel qui a ťtťla notre jusqu'ŗprťsent pour
introduire des opťrations avec effet de bord sur les objets
manipulťs.
Soient donc les procťdures setHead et setTail qui
modifient, respectivement, la valeur de l'ťlťment contenu en
tÍte et la valeur de la suite de la liste passťe en premier argument.
Procedure setHead(xs:DList, x:D);
Begin
hd(xs)^ := x;
End;
Procedure setTail(xs:DList, ys:DList);
Begin
tl(xs) := ys;
End;
La procťdure setHead fait exactement la modification en place
de la valeur du premier ťlťment de la liste. Pour obtenir une
fonction de concatťnation procťdant par effet de bord, nous nous
donnons une fonction auxiliaire lastTail retournant la
derniŤre cellule, de type DLIst d'une
liste3
ou nil si la
liste est vide.
Function lastTail(xs:DList) : DList;
Begin
If xs = nil then lastTail := nil
Else If tl(xs) = nil then lastTail := xs
Else lastTail := lastTail(tl(xs))
End;
On dťfinit alors une nouvelle fonction de concatťnation DListCat4
comme :
Procedure DListCat(xs:DList, ys:DList);
Begin
setTail(lastTail(xs), ys);
End;
Commentaire (1) : Nous avons choisi ŗdessein d'implanter setHead, setTail
et DLIstCat comme des Procedure et non des Function. Une procťdure ne retourne pas de valeur. Si elle a un
effet, c'est un effet de bord. C'est pour souligner cette
propriťtťde setHead, setTail et DLIstCat que
nous utilisons une dťfinition comme Procedure.
Exercice (3) : Soit f une fonction de signature Function f(x:D) : D,
ťcrire une procťdure qui remplace tous les ťlťments x
d'une liste xs par le rťsultat de f(x).
Soit p une procedure de signature Procedure p(x:D),
ťcrire une procťdure qui applique ŗtous les ťlťments x d'une liste xs la procťdure p.
Exercice (4) : On pose Type D = Integer;.
Ecrire une procťdure d'affichage des listes d'entiers.
On souhaite, par exemple, que la liste obtenue
par Cons(1, Cons(2, Cons(3, Nil))) soit affichťe sous la forme
[1;2;3] et que la liste vide soit affichťe sous la forme [].
Ecrire une fonction intListOfString de signature
Function intListOfString(s:String) : DList qui analyse une
chaÓne de caractŤre sensťe contenir une liste au format
ci-dessus et renvoie la liste (de type DList) correspondante.
Exercice (5) : Proposez un amendement de la structure de listes de faÁon ŗce que la fonction lastTail soit immťdiate.
2. Les arbres
Les arbres, comme les listes, peuvent Ítre vues comme des structures
rťcursives des stockages de donnťes. Il y a quelques variantes sur
l'endroit oýles donnťes sont rangťes dans la structure : ŗchaque niveau de l'arbre; seulement au plus bas niveau; ou
partout. L'autre variante possible est le nombre d'embranchements :
arbres binaires; arbres ternaires voire arbres dits planaires
gťnťraux. C'est cette derniŤre variante que nous utiliserons.
Nous nous permettrons d'utiliser le simple terme d'arbre pour
dťsigner de telles structures.
(2.d) Considťrations abstraites
Comme nous l'avons fait pour les listes, dťfinissons abstraitement
l'ensemble de arbres planaires gťnťraux, dits aussi arbres ŗembranchements finis, en termes de constructeurs :
- un arbre peut Ítre vide, on notera Empty ;
- pour tout entier n, si t1, .., tn sont des arbres et x
un ťlťment alors on peut construire l'arbre de racine x
dont les sous-arbres sont t1, .., tn, on notera Brn(x, t1, ..,
tn).
La constante Empty et l'infinitťd'opťrateurs Brn sont les
constructeurs des arbres.
Voici un exemple de reprťsentation graphique d'un arbre
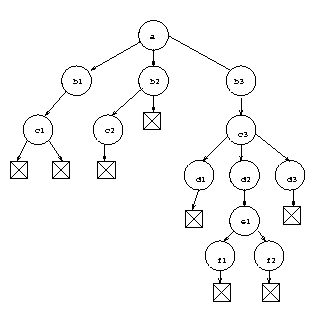
Son ťcriture linťaire correspondante est :
|
Br3(a, |
Br1(b1,Br2(c1,Empty,Empty)), |
| |
Br2(b2, Br1(c2, Empty), Empty), |
| |
Br1(b3, Br3(c3, |
Br1(d1, Empty), |
| |
|
Br1(d2, Br2(e1, Br1(f1, Empty), Br1(f2, Empty))), |
| |
|
Br1(d3, Empty))))
|
Comme l'illustre notre exemple, une telle dťfinition des arbres
multiplie de faÁon incontrolable l'utilisation de l'arbre vide pour
``terminer'' la structure. Nous choisirons une dťfinition
alternative dans laquelle nous remplaÁons le constructeur Empty
par un constructeur Leaf : une feuille contenant uniquement un
ťlťment de donnťe. Ce qui conduit ŗla dťfinition suivante.
- si x est un ťlťment alors Leaf(x) est un arbre.
- pour tout entier n, si t1, .., tn sont des arbres et x
un ťlťment alors Brn(x, t1, .., tn) est un arbre.
Notre exemple se dessine alors
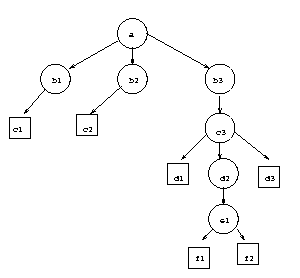
et s'ťcrit
|
Br3(a, |
Br1(b1,Leaf(c1)), |
| |
Br1(b2, Leaf(c2), |
| |
Br1(b3, Br3(c3, |
Leaf(d1), |
| |
|
Br1(d2, Br2(e1, Leaf(f1), Leaf(f2))), |
| |
|
Leaf(d3))))
|
Nous avons perdu la possibilitťd'avoir un arbre vide, mais
certaines application, dont celle que nous avons en tÍte, s'en
passent trťs bien !
(2.e) Un codage avec les listes
PlutŰt que de considťrer une famille de constructeurs Brn oýn est un entier, on peut ne considťrer qu'un seul constructeur
binaire dont le second argument est la liste des sous-arbres. On
obtient alors la dťfinition :
- si x est un ťlťment alors Leaf(s) est un arbre.
- si x est un ťlťment et ts une liste d'arbres alors
Br(x,ts) est un arbre.
Notons que nous rťintroduisons subreptissement la possibilitťde
construire de fausses feuilles en utilisant une liste vide
de sous arbres : Br(x,Nil).
Les sous-arbres de la dťfinition rťcursives sont ici encapsulťs
dans la structure de liste ts. On n'y a pas accťs directement,
mais en dťstructurant la liste. On aura donc sur les arbres
planaires ainsi dťfinit un style de programmation particulier.
Par exemple, on dťfinira une fonction de transformation d'un arbre
en liste5
ŗl'aide deux deux fonctions mutuellement rťcursives : listOfTree et listOfTrees.
| listOfTree(Leaf(x)) |
= |
Cons(x, Nil) |
| listOfTree(Br(x,ts)) |
= |
Cons(x, listOfTrees(ts)) |
| |
|
|
| listOfTrees(Nil) |
= |
Nil |
| listOfTrees(Cons(t,ts)) |
= |
append(listOfTree(t), listOfTrees(ts))
|
(2.f) Implantation
Pour implanter notre structure d'arbre, nous devons dťfinir ŗla fois les arbres et les listes d'arbres. De plus, nous devons
distinguer parmi les arbres ceux qui sont de simples feuilles de ceux
qui sont des branchements.
Le premier point ne pose pas de difficultťpuisque les listes sont
des pointeurs et peuvent Ítre dťclarťes avant la
dťfiniton de l'objet sur lequel elles pointent. Pour rťaliser le
second point, il faut pouvoir dťfinir un type dit type
union. Le langage PASCAL propose pour cela une catťgorie
particuliŤre d'enregistrements dits variables oķun champs,
pris dans un type ťnumťrť, sert de marqueur entre les
diffťrentes sortes de donnťes.
Type
TList = ^TItem;
TPtr = ^DTree;
TItem =
Record
head : TPtr;
tail : TList;
End;
TSort = (leafT, brT);
DTree =
Record
elt : DPtr;
Case tag:TSort of
brT : (subTrees : TList);
End;
Exercice (6) : Implanter le constructeur ConsTList, les destructeurs hdTList et tl TList ainsi que la fonction de concatťnation
TListCat pour les listes d'arbres (remarquons que l'on peut
conserver la constante Nil pour la liste d'arbre vide)
Exercice (7) : Dťfinir les constructeurs Leaf et Br des
arbres. Dťfinir les destructeurs eltOf et subTreesOf
ainsi que deux fonctions de reconnaissance : isLeaf et isBr.
Muni de ces functions de base, on peut implanter les fonction
mutuellement listOfTree et listOfTrees en utilisant la
directive forward permettant de dťclarer une fonction avant de
la dťfinir effectivement.
Function listOfTrees(ts : TList) : Dlist ; Forward ;
Function listOfTree(t : DTree) : DList ;
Begin
If isLeaf(t) then listOfTree := Cons(eltOf(t), Nil)
Else listOfTree := Cons(eltOf(t), listOfTrees(subtreesOf(t)))
End;
Function listOfTrees(ts : TList) : DList;
Begin
If (ts=Nil) then listOfTrees := Nil
Else listOfTrees := appendTList(listOfTree(hdTList(ts)),
listOfTrees(tlTList(ts)))
End;
Exercice (8) : Ecrire une procťdure d'affichage des arbres sous forme
linťaire (on affichera les listes comme en dans l'exercice
X)
ß II -- Les termes : dťfinition, implantation
3. Dťfinition
Les mathťmatiques, aussi bien que l'informatique vous ont habituťs
ŗmanipuler des termes que l'on appelle plus volontier expressions en informatique. Par exemple, 1+(3◊ 4),
1+(2◊ x), f(x)+1 sont des termes. On reconnait dans les
termes trois catťgories de symboles : les constantes (1, 2,
etc..) les variables (x, etc..) et les fonctions (+, ◊,
f, etc..) On peut uniformiser la notation des termes qui mťlange
ici notation infixe et notation prťfixe des fonctions en ne
dťcrťtant valide que la seule notation prťfixe. Ce que l'on
ťcrit usuellement 1+(f(x)◊ 2) devient alors : +(1,
◊(f(x),2)).
De faÁon gťnťrale, on dťfinit un ensemble
de termes par la donnťe de trois ensembles de symboles et de deux
(ou trois) rŤgles de construction des termes. On ne se soucis pas
encore d'interprťter les symboles (ie : on utilise le
symbole + sans soucis de savoir qu'il reprťsente l'addition). En
d'autre termes : on dťfinit une syntaxe sans en donner la sťmantique.
Soient donc
- C un ensemble fini ou dťnombrable de symboles de constantes,
- X un ensemble dťnombrable de symboles variables,
- F un ensemble fini ou dťnombrable de symboles de fonctions.
On demande que ces trois ensembles soient deux ŗdeux disjoints.
Chaque fonction mathťmatique (ou informatique) rťclame un nombre
donnťd'arguments : l'addition a besoin de deux arguments, la
fonction logarithme n'en a besoin que d'un. On dit que l'addition est
binaire alors que la fonction logarithme est unaire. On
dit aussi que l'addition est d'aritť 2 alors que la fonction
logarithme est d'aritť1. Pour ťcrire correctement un terme, il
faut connaÓtre l'aritťdes symboles de fonction. On munit donc
l'ensemble F d'une fonction d'aritťa : FģIN
Si főF et a(f)=n, pour nőIN, nous dirons que f
est d'aritťn ou que f est n-aire (prononcer :
``Ťnaire'')
Nous pouvons ŗprťsent dťfinir rťcursivement l'ensemble
T des termes par :
- CŐT (tout symbole de constante est un terme) ;
- XŐT (tout symbole de variable est un terme) ;
- pour tout t1ő T, .., tnő T, pour tout főF si
a(f)=n alors f(t1, .., tn)ő T (si f est un symbole de
fonction d'aritťn et t1, .., tn sont des termes, alors
l'application de f aux n arguments t1, .., tn est un terme).
On a que tout terme t est soit une variable xő X, soit une
constante cő C, soit de la forme f(t1, .., tn) avec fő F
et t1, .., tn des termes. On utilisera ces diffťrents cas de
construction des termes pour dťfinir (rťcursivement, dans la
plupart des cas) propriťtťs ou fonctions sur les termes. Par
exemple on dťfinit l'ensemble des variables apparaissant dans un
terme t, que l'on note V(t), par :
- si t est une constante alors V(t)=ō
- si t est la variable x alors V(t)={x}
- si t est de la forme f(t1, .., tn) alors V(t) =
»i=1nV(ti)
Un notion utile sur les termes est celle de sous
terme. Intuitivement, un terme t' est un sous terme de t si t'
<< apparaÓt >> dans t. Plus formellement, on dťfinit,
rťcursivement sur t, l'ensemble ST(t) des sous termes de t
- Si t est une variable ou une constante alors ST(t)={t}.
- Si t est de la forme f(t1, .., tn) alors
ST(t) = {t}»»i=1nST(ti)
On dit que v est un sous terme de t si et seulement si vő ST(t).
4. Implantation
L'ťcriture des termes telle que nous venons de la dťfinir rappelle
ce que nous avions appelťnotation linťaires des arbres. On
peut donc, ŗl'inverse, reprťsenter graphiquement les termes par
des structures arborescentes. Ainsi, le terme +(1,*(f(x),2))
peut Ítre dessinťcomme l'arbre :

Notre implantation de la structure des termes sera donc fortement
inspirťe de celle des arbres. Chaque noeud sera ťtiquetťpar
un nom de symbole. Dans le cas oýce symbole est un symbole de
fonction, nous aurons autant de sous arbres que l'indique l'aritťdu
symbole.
Type
TList = ^TItem;
Term = ^TData;
TItem =
Record
head : Term;
tail : TList;
End;
TSym = (varSym, cstSym, funSym);
TData =
Record
name : String;
Case tag:TSym of
funSym : (args : TList);
End;
On se donne, sur les termes (et les listes de termes) les
primitives suivantes :
Termes : constructeurs
Function TCst(c : String) : Term;
Function TVar(x : String) : Term;
Function TFun(f : String; ts : TList) : Term;
Termes : accesseurs
Function nameOf(t : Term) : String;
Function symOf(t : Term) : TSym;
Function argsOf(t : Term) : TList;
Modificateur physique
Procedure setTerm(Var t : Term; u : Term);
Listes de termes : constructeur
Function ConsTList(t:Term; ts:TList) : TList;
La liste vide reste le pointeur nul : Nil
Listes de termes : accesseurs
Function hdTList(ts:TList) : Term;
Function tlTList(ts:TList) : TList;
Exercice (9) : Dťfinir une fonction d'affichage des termes (cf affichage
des arbres).
Exercice (10) : Dťfinir une fonction boolťenne qui prend en argument deux
termes t et v et retourne true si et seulement si
v est un sous terme de t.
5. De l'ťgalitťentre termes
Considťrons les deux termes suivants : 2+2 et 2*2. Nul ne
s'ťtonnera que l'on ťcrive 2+2=2*2. Cependant, ces deux termes ne sont pas ťgaux ! L'arbre reprťsentant 2+2 et l'arbre
reprťsentant 2*2 ne sont pas la mÍme structure. A
l'inverse, le mÍme terme peut dťsigner deux objets diffťrents :
par exemple, on peut avoir que 1+1=2 si l'on utilise le symbole +
pour dťnoter l'addition sur les entiers, mais on peut avoir
ťgalement que 1+1=1 si l'on utilise le symbole + pour dťnoter
la disjonction boolťenne.
Il nous faut donc distinguer deux catťgories d'ťgalitť:
l'ťgalitťusuelle que l'on manipule lorsque l'on a assignťune
interprťtation aux symboles de fonctions (et de constantes) ;
l'ťgalitťstructurelle qui ne considŤre que l'identitťd'ťcriture ou de reprťsentation des termes.
Exercice (11) : dťfinir une fonction boolťenne eqT qui teste
l'ťgalitťstructurelle entre deux termes.
Au niveau du langage PASCAL, on retrouve ťgalement cette dichotomie
entre l'ťgalitťdu langage dťnotťe par le symbole = et
l'ťgalitťstructurelle dťfinie par la fonction eqT. Dans
le cas de notre structure Term, si le rťsultat de t=u est
True, nous dirons que t et u sont physiquement
ťgaux : leurs reprťsentations partagent exactement le mÍme
espace mťmoire.
Duplication
Nous aurons besoin par la suite de dupliquer un terme ou un sous terme
donnť. C'est ŗdire, crťer une copie u d'un terme
donnťt telle que eqT(t,u)=True, mais t et
u sont physiquement diffťrents (au quel cas : t=u=False) On dťfinit pour cela une fonction de clonage : cloneT
Function itCloneT(ts : TList) : TList; Forward;
Function cloneT(t : Term) : Term;
Begin
Case symOf(t) of
varSym : cloneT := TVar(nameOf(t));
cstSym : cloneT := TCst(nameOf(t));
funSym : cloneT := TFun(nameOf(t), itCloneT(argsOf(t)));
End;
End;
Function itCloneT(ts : TList) : TList;
Begin
If ts=Nil then itCloneT := Nil
Else itCloneT := ConsTList(cloneT(hdTList(ts)), itCloneT(tlTList(ts)));
End;
Dťsallocation
Les clones que nous crťerons seront, pour la plus part, des
structures temporaires. Pour ne pas encombrer inutilement la
mťmoire, nous devrons libťrer cet espace. On utilise pour cela la
primitive dispose de PASCAL.
Procedure itDisposeT(Var ts : TList); Forward;
Procedure disposeT(Var t : Term);
Var aux : TList;
Begin
If t<>Nil then
Begin
If symOf(t)=funSym then
Begin
aux := argsOf(t);
itDisposeT(aux);
End;
dispose(t);
t := Nil;
End;
End;
Procedure itDisposeT(Var ts : TList);
Var aux1 : TList;
Var aux2 : Term;
Begin
If ts<>Nil then
Begin
aux2 := hdTList(ts);
disposeT(aux2);
aux1 := tlTList(ts);
itDisposeT(aux1);
dispose(ts);
ts := Nil;
End;
End;
ß III -- Substitution
6. Dťfinition
Formellement, une substitution est une application de l'ensemble
des variable X dans l'ensemble des termes T. Si s est une
substitution, on peut l'ťtendre en une application de l'ensembles
des termes dans l'ensemble des termes. Par abus de langage, on
continue d'appeler substitution s cette nouvelle
application. Intuitivement, si t est un terme, le terme sigma(t)
est le terme obtenu en remplaÁant chaque variable x de t par le
terme s(x). Formellement, on dťfinit rťcursivement
s(t) par :
- si t est une constante c, s(t)=c ;
- si t est une variable x, s(t)=s(x) ;
- si t est de la forme f(t1, .., tn),
s(t)=f(s(t1), .., s(tn))
Dans la pratique, les substitutions sont rarement dťfinies sur
l'ensemble des variables dans son entier. On se contente de remplacer
un nombre fini (et souvent petit) de variables. Une substitution est
alors une liste (finie) d'association dont les clťs sont les noms de
variables et les valeurs associťes, des termes. On notera [u1/x1,
.., um/xm] les substitutions et t[u1/x1, .., um/xm] le terme
obtenu par application de la substitution. Ce terme est dťfini par :
- si t est une constante c, t[u1/x1, .., um/xm]=c ;
- si t est une variable x telle que xŌ{x1, ..,
xm}, t[u1/x1, .., um/xm]=x ;
- si t est une variable xiő{x1, ..,xm},
t[u1/x1, .., um/xm]=ui ;
- si t est de la forme f(t1, .., tn),
t[u1/x1, .., um/xm]=f(t1[u1/x1, .., um/xm], .., tn[u1/x1,
.., um/xm])
Remarquons que si nous voulons que les substitutions reprťsentťes
sous la forme [u1/x1, .., um/xm] restent des applications, il
faut supposer que les variables x1, .., xm sont deux ŗdeux
distinctes.
7. Implantation
Pour constituer les listes d'association qui reprťsentent les
substitutions, nous commenÁons par dťfinir le type des paires
(variable, terme) Nous ne retiendrons des variables que leur nom, et,
tenant compte de la remarque X, nous manipulerons les
paires via un pointeur. Ce qui donne :
Type
STPair = ^STItem;
STItem =
Record
key : String;
val : Term;
End;
Exercice (12) : nous laissons en exercice l'implantation du constructeur
Function newSTPair(x : String; t : Term) : STPair;
et des accesseurs :
Function keyOf(xt : STPair) : String;
Function valOf(xt : STPair) : Term;
Nous recommandons ťgalement l'ťcriture d'une fonction d'affichage
des paires sous la forme t/x
On dťfinit alors le type LSubst comme liste d'association,
selon notre procťder habituel :
Type
LSubst = ^SItem;
SItem =
Record
head : STPair;
tail : LSubst;
End;
Exercice (13) : Comme d'hab'
Function ConsLSubst(xt:STPair; xts:LSubst) : LSubst;
Function hdLSubst(xts:LSubst) : STPair;
Function tlLSubst(xts:LSubst) : LSubst;
Procedure writeLSubst(xts : LSubst);
Avec, en plus
Procedure disposeLSubst(Var xts : LSubst);
Procedure setTlLSubst(xts : LSubst; yus : LSubst);
La fonction assocLSubst de recherche de valeeur associťe ŗune clťpeut ťchouer. Ce qu'il faut pouvoir signaler au code
appelant. Nous profiterons ici de ce que les valeurs associťes sont
de pointeurs (cf type Term) pour utiliser le pointeur nul
comme constat d'ťchec. En notant (y,v) les paires, la
spťcification ťquationnelle de la fonction assoc, en
gťnťral, est
| assoc(x,Nil) |
= |
Nil |
|
| assoc(x,Cons((y,v), yvs) |
= |
v |
, si y=x |
| assoc(x,Cons((y,v), yvs) |
= |
assoc(x, yvs) |
, sinon
|
Exercice (14) : Ecrire Function assocLSubst(x:String; xts:LSubst) : Term;
L'application d'une substitution ŗun terme est implantťpar la
procťdure
Procedure itSubst(ts:TList; xts:LSubst); Forward;
Procedure subst(t:Term; xts:LSubst);
Var aux : Term;
Begin
Case symOf(t) of
varSym : Begin
aux := assocLSubst(nameOf(t), xts);
If aux <> Nil then setTerm(t, cloneT(aux));
End;
funSym : itSubst(argsOf(t), xts)
End;
End;
Procedure itSubst(ts:TList; xts:LSubst);
Begin
If ts<>Nil then
Begin
subst(hdTList(ts), xts);
itSubst(tlTList(ts), xts);
End;
End;
Remarquons que dans le cas oýla substitution est effective (le
terme t est une variable), nous procťdons (d'oýla
Procedure) ŗune modification en place du terme (procťdure
setTerm) et, de plus, nous opťrons la substitution avec un
clone du terme associť(aux) ŗla variable. L'utilisation du
clone permet d'ťviter, si la variable a plusieurs occurences dans
t, le partage de la reprťsentation d'un mÍme sous terme : ce
partage n'est pas souhaitable pour l'application que nous avons en
vue.
8. Construction des substitutions
Enfin, pour la suite des ťvťnements, nous aurons besoin d'une
fonction addLSubst d'enrichissement des substitutions. Cette
fonction devra rajouter une nouvelle paire (y,v) ŗune liste yvs
si et seulement si ou bien (y,v) n'apparaÓt pas dans yvs. Dans
le cas oýyvs contiendrait une paire (y,w) avec wĻv, la
fonction devrait signaler une erreur que nous appellerons un clash.
Pour implanter cette fonction, nous nous donnons les impťratifs :
faire une modification en place de la liste yvs
laisser inchangťe la liste yvs en cas de redondance ((y,v) existe
dťjŗ) ou de clash
Ces deux impťratifs nous conduisent ŗimplanter une
Procedure plutŰt qu'une fonction. Et comme nous ne pourrons
utiliser l'astuce du pointeur nul comme constat d'ťchec, cette
procťdure aura comme argument un boolťen siganlant l'occurrence
d'un clash ou non. On obtient
Procedure addLSubst(Var clash : boolean; Var xts : LSubst; xt : STPair);
Var aux1 : STPair;
Procedure addSubstRec(Var xts : LSubst);
Var aux2 : LSubst;
Begin
If xts=Nil then
xts := ConsLSubst(xt,Nil)
Else
Begin
aux1 := hdLSubst(xts);
If keyOf(aux1)=keyOf(xt) then
clash := not (eqT(valOf(aux1),valOf(xt)))
Else
Begin
aux2 := tlLSubst(xts);
addSubstRec(aux2);
setTlLSubst(xts, aux2);
End;
End;
End; { addSubstRec }
Begin { addLSubst }
clash := False;
addSubstRec(xts);
End; { addLSubst }
ß IV -- Filtrage
9. Dťfinition
On appelle filtrage une relation entre termes mettant en
oeuvre les subtitutions. On dit qu'un terme t filtre un
terme u si et seulement si il existe une substitution s telle
que s(t)=u. Nous dirons, plus prťcisťment que t filtre
u selon s.
Par exemple, si t est le terme n+0 et que u est le terme
(m+1)+0 (oýn et m sont des variables) alors, en prenant
s=[m+1/n] on obtient t[m+1/n]=u On peut dire que si t
filtre u alors u est un cas particulier de t : on obtient u en
remplaÁant dans t certaines variables par des termes
particuliers. Un cas particulier de filtrage est celui oýles deux
termes sont dťjŗťgaux : 0+1 filtre 0+1 selon la
substitution vide [].
Il faut prendre garde que les substitutions sont des fonctions : elles
ne peuvent associer des termes diffťrents ŗune mÍme
variable. Ainsi le terme n+n ne filtre pas 0+1, ni 0+m, ni m+p
(oýn, m et p sont les variables)
Le problŤme que nous aurons ŗtraiter est : ťtant donnťs deux
termes t et u, est-ce que t filtre u, et, si oui, quelle est
la substitution qui ťgalise les deux termes ? Il nous faut pour cela
une dťfiniton plus constructive de la relation de
filtrage. Cette nouvelle dťfinition nous permettra de donner un
algorithme dťcidant de la question du filtrage entre deux termes.
Selon l'habitude maintenant bien ťtablie, nous procťderons par
rťcurrence sur la structure des termes pour donner une premiŤre
redťfinition de la relation de filtrage.
- si t est la variable x alors t filtre u selon [u/x].
- si t est la constante c ainsi que u alors t filtre u
selon [].
- si t est de la forme f(t1, .., tn), si u est de la
forme f(u1, .., un) et si, pour tout iő[1..n], ti filtre
ui selon s alors t filtre u selon s.
- tout autre cas est un cas d'ťchec appelťclash.
Si cette dťfinition permet de dťcider du cas trivial du filtrage
(lorsque t est une variable) elle reste encore trop gťnťrale
pour le cas oýt est de la forme f(t1, .., tn) : on ne sait
toujours pas comment construire s.
En examinant ce dernier cas, nous avons que si chaque ti filtre
chaque ui selon une substitution si, pour que t filtre u
il faut obtenir ŗpartir des si une seule substitution
s. Pour cela, il faut simplement que les si soient
cohťrentes : qu'elles associent chacune un mÍme terme aux
mÍmes variables. Si tel est le cas, on fusionne toutes les
si en une seule substitution. On notera
s1Ňs2 la fusion des substitions s1 et
s2.
Exercice (15) : ťcrire la fonction de fusion (indication : utiliser la
procťdure addLSubst)
10. Algorithme
Sachant que l'on peut traiter localement les sous termes t1, ..,
tn, reste encore, pour obtenir une dťfinition complŤtement
constructive, ŗťliminer les points de suspension (..) de
l'ťcriture des termes. Nous utilisons pour ce faire le remplacement
des n-uplets t1, .., tn par des structures de listes. Pour
construire la substitution s rťsultant de la fusion des
s1, .., sn, nous procťdons pas ŗpas par induction
structurelle sur les listes de termes ŗcomparer.
On retrouve alors notre schŤma de dťfinitions mutuellement
rťcursives et on dťfinit ŗla fois le filtrage entre termes et le
filtrage entre listes de termes :
- Filtrage entre termes :
- si t est la variable x alors t filtre u selon [u/x].
- si t est la constante c ainsi que u alors t filtre u
selon [].
- si t est de la forme f(ts), si u est de la forme f(us)
(oýts et us sont deux listes de termes) et si ts filtre us
selon s alors t filtre u selon sigma.
- sinon, on a un clash.
- Filtrage entre listes de termes :
- si ts et si us sont toutes deux la liste vide [] alors
ts filtre us selon la substitution vide [].
- si ts est de la forme Cons(t, ts'), si us est de la forme
Cons(u, us'), si le terme t filtre le terme u selon la
substitution s et si la liste ts' filtre la liste us' selon
la substitution s' alors ts filtre us selon
sŇs'.
- dans tout autre cas, on a un clash.
Exercice (16) : implanter l'algorithme ci-dessus par deux procťdures :
Procedure match(t:Term; u:Term; Var s:LSubst; Var clash:Boolean);
Procedure itmatch(ts:TList; us:TList; Var s:LSubst; Var clash:Boolean);
La liste s contiendra, si elle existe, la substitution selon
laquelle t (resp. ts) filtre u (resp. us). Le
boolťen clash indiquera s'il y a ou non un clash entre
les (listes de) termes.
11. Recherche de motif
Dans le cadre de la rťťcriture, nous utiliserons la relation de
filtrage de la fa con suivante : soit p un terme appelťmotif (en anglais pattern) et soit t un terme, le problŤme
que nous cherchons ŗrťsoudre est celui de savoir s'il existe un
sous terme t' de t tel que p filtre t.
L'algorithme de recherche d'un motif p dans un terme t est
simple. Il procŤde par induction mutuelle sur les termes et listes
de termes. Nous demanderons, qu'en cas de succť, il fournisse ŗla
fois la substitution et le sous terme filtrť. En supposant que l'on
a une fonction match telle que match(p,t)=s si p filtre t
selon s et match(p,t)=clash sinon, on dťfinit deux
fonctions tryMatch et itTryMatch par le systŤme d'ťquations
| tryMatch(p,t) |
= |
(s, t) |
, si match(p,t)=s |
| tryMatch(p,f(ts)) |
= |
itTryMatch(p,ts) |
, si match(p,f(ts))=clash |
| |
|
|
|
| itTryMatch(p,[]) |
= |
clash |
|
| itTryMatch(p, Cons(t,ts') |
= |
(s, t) |
, si tryMatch(p,t)=s |
| itTryMatch(p, Cons(t,ts') |
= |
itTryMatch(p,ts) |
, sinon
|
Exercice (17) : Implanter l'algorithme de recherche de motif par deux
procťdures :
Procedure tryMatch(p : Term; t:Term; Var s:LSubst; Var clash:boolean; Var v:Term);
Procedure itTryMatch(p : Term; ts:TList; Var s:LSubst; Var clash:boolean; Var v:Term);
Les rťsultats seront donnťs dans les variables s et clash.
ß V -- RŤgles de rťťcriture
Nous abordons maintenant l'ultime ligne droite avant la mise en
application des systŤmes de rťťcriture. Nous allons voir dans ce
paragraphe ce qu'est une rŤgle de rťťcriture, comment
plusieurs rŤgles se combinent pour former un systŤme de
rťťcriture et, enfin, comment appliquer ces rŤgles pour
dťfinir une relation de rťťcriture.
Une rŤgle de rťťcriture un couple de termes (l,r)
que l'on note lģ r. Une rŤgle de rťťcriture est donc
orientťe. Le terme l est le membre gauche de
la rŤgle et r est son membre droit.
Intuitivement, pour appliquer une rŤgle lģ r ŗun terme
t, on cherche un sous terme t' de t tel que l filtre t'
selon, disons, s, puis on remplace le sous terme t' par celui
obtenu en appliquant s ŗr.
12. Dťfinitions
Nous donnons dans ce paragraphe la dťfinition formelle de la
relation de rťťcriture. Il nous faut, pour y parvenir, prťciser
la notion intuitive de << remplacement >> d'un sous terme.
Considťrons le terme f(g(a,h(x)), h(x)). Si nous nous contentons
de dire << nous remplaÁons le sous terme h(x) par b >>
Pour profťrons un ťnoncťambigu : lequel des deux h(x) faut-il
remplacer ? Pour lever cette ambiguÔtť, nous introduisons la
notion d'occurence qui a pour rŰle de permettre de dťsigner
sans ambiguÔtťun sous terme d'un terme.
Rappelons nous que les termes ont une structure
d'arbre. Intuitivement, on peut dťnoter un sous arbre d'un arbre, en
indiquant le chemin que l'on parcours, en partant de la racine,
pour atteindre ce sous arbre. Pour noter les chemins, on utilise les
suites finies (possiblement vides) d'entiers strictement positifs. On
note la suite vide et, si x est une suite et i un
entier (strictement positif), on note i.x la suite commenÁant par
i et se poursuivant par x.
Dans le domaine de la rťťcriture (et des termes) on parle d'occurence plutŰt que de chemin. On dťfinit, par induction sur t
l'ensemble O(t) des occurences de t.
- O(t)=, si tőC ou tőX,
- O(t)={}»{i.o | iő[1..n] et
oőO(ti)}, si t=f(t1, .., tn).
Si oőO(t), on dťfinit le sous terme de t d'occurrence
o, notťt|o par les deux clauses :
- t|= t et
- f(t1, , ti, .., tn)|i.o = ti|o.
Si oőO(t), on dťfinit l'opťration de remplacement d'un
terme u ŗl'occurrence o de t, notťe t[o¨ u], par
les deux clauses :
- t[¨ u]=u et
- f(t1, , ti, .., tn)[i.o¨ u] = f(t1, ..,ti[o¨
u], .., tn).
Si lģ r est une rŤgle de rťťcriture, on dit qu'elle est
applicable ŗun terme t si et seulement si il existe
oőO(t) telle que l filtre t|o selon s. Lorsqu'une
rŤgle lģ r est applicable ŗun terme t (ŗune
occurence o, selon une substitution s) le rťsultat de
l'application de cette rŤgle ŗce terme est le terme
t' = t[o¨ s(r)] on dit que t se rťťcrit (par
lģ r) en t', on note tģ t'. En itťrant le
processus de rťťcriture sur chaque nouveau rťsultat obtenu, on
obtient une chaÓne de rťťcritures. Si le dernier terme
de cette chaÓne est u, on note t ģ* u.
Un ensemble de rŤgles de rťťcriture forment un systŤme de
rťťcriture. Si R est un systŤme de rťťcriture, on dit
qu'un terme t se rťťcrit en t' selon R si et seulement
il existe une rŤgle lģ r de R telle que t se
rťťcrit, par lģ r, en t'. On note
tģ*Rt' ou simplement tģ*t'
lorsqu'il n'y a pas ambiguÔtťsur le systŤme de rťťcriture.
- 1
- La seule exception ťtant le passage par
rťfťrence ŗune fonction
- 2
- En fait, on ŗallouťdeux pointeurs : un pour le
champs head de la structure DItem et un second pour la
nouvelle liste elle-mÍme.
- 3
- A ne pas confondre avec last
- 4
- Par analogie avec le strcat de C.
- 5
- Parcours prťfixe
This document was translated from LATEX by HEVEA.